How we prune RAG context
Dropping two-thirds of retrieved chunks while keeping 96% recall

by
Lars Baltensperger
Kapa is a RAG (retrieval-augmented generation) system for technical documentation. Developers use our retrieval API to give the agents they build context about their product, and the same retrieval layer powers our end-to-end AI assistants.
A RAG system generally has two parts: a retriever, which finds the chunks of documentation relevant to a question (short passages cut from larger documents), and a generator, the LLM that writes the answer from them. The retriever works like a funnel: cheap steps handle the large volumes, and more expensive steps only see what survives. Embedding and keyword search cut the knowledge base, often hundreds of thousands of chunks, down to a few hundred candidates; a reranker puts those in order; and only the top chunks reach the generator, the largest and most expensive model in the chain. The generator reads and is billed for every one of those final chunks, yet even after all that filtering, most are still not needed for the question at hand. That is deliberate: retrievers aim for maximum recall and trust the generator to ignore the noise. But ignored chunks still cost money.
Pruning adds one more step: a much smaller model that throws out the chunks the answer will not need, before the most expensive model reads them. You sacrifice a tiny amount of recall accuracy and add a little latency for a much smaller context, and the smaller context reduces cost significantly. What follows is the research we did on different ways to implement pruning, what we found works best, and what we shipped to production.
Compression versus recall
Compression is how many of the retrieved chunks you drop, and it is what you want to maximize, because chunks are where the money goes. In our end-to-end assistants, where we generate the answer ourselves, the retrieved chunks are about two-thirds of the total cost of a query, far more than the generated answer, the conversation history, or the system prompt.

The savings are linear: every chunk fewer we return cuts the total cost of a query by about 4%. If you feed the chunks to your own model instead, the exact split will differ, but the shape holds: chunks dominate the cost, and pruning them is where the savings are.
Recall is the other side: it measures whether the chunks necessary to answer the question survived. Drop a load-bearing chunk and you might have saved some money, but at the cost of producing a wrong answer, and the fewer chunks you return, the more likely that becomes. The quality of a pruner is the quality of the tradeoff it offers: how much compression it buys per point of recall it costs.
Why you cannot just reuse your reranker
Our retriever already uses reranking to arrive at the top K chunks it returns to the generator. So we are sometimes asked to expose the rerank scores and let callers cut on them directly, keep everything above 0.7, drop the rest. It sounds like a reasonable request, but it fails for two reasons.
The scores are an ordering, not a measurement
A rerank score orders chunks. It says chunk A is more relevant than chunk B for this query, and nothing more. The scores are not calibrated: a 0.8 on one query does not mean what a 0.8 means on the next, so no single cutoff works across your traffic. Cohere's guidance says exactly this: relevance scores are query-dependent, and a filtering threshold has to be recalibrated for each type of query. The only cutoff a ranking robustly supports is positional, keep the top N, and a top-N cutoff drops the last chunk whether it is noise or the answer itself.
Relevance is not a property of a single chunk
Even a perfectly calibrated score would miss something more fundamental. The commonly used rerankers are pointwise cross-encoders: they score each query-document pair on its own, never a chunk alongside the other chunks it was retrieved with. (Listwise rerankers exist, but they are not what most pipelines use.) That would be fine if relevance were a property of a single chunk, but it is not. A chunk can be relevant in three ways:
Direct relevance: the chunk answers the question by itself.
Partial relevance: the chunk answers only one part of the question, so a reranker does not score it as fully relevant. But different chunks may answer the other parts, and together they answer the question.
Indirect relevance: the chunk is not directly meaningful for the question, but it explains another chunk that is: it supplies the definition, prerequisite, or disambiguation without which the relevant chunk cannot be understood.
A pointwise score only fully captures the first kind. The other two types receive scores that do not reflect their real value: a partially relevant chunk scores middling, and a chunk that merely defines a term reads as noise. A chunk can be worthless on its own yet essential in combination, so the real question is not whether a chunk is relevant by itself, but whether it belongs to a set that together answers the question. That is a judgment no isolated score can make.
What we considered
There are agentic approaches to pruning, in which the retrieving agent curates or edits its own context as it works. But they presuppose an agentic retriever, and not all of our retrieval modes are agentic: the one behind our retrieval API in particular is a latency-sensitive single pass. So we only considered post-filtering, an independent step that takes the final set of chunks, whatever produced it, scores them, and forwards only those worth keeping. Within post-filtering we considered four approaches.
Anchor-document pruning
This approach, proposed by Sinhababu et al., makes the reranker's scale absolute by planting chunks of known relevance into the ranking. You define a few relevance levels, say Essential down to Unrelated, and for each level an LLM writes one synthetic chunk with exactly that degree of relevance to the query: one that would fully answer it, one that has nothing to do with it, and so on. The synthetic chunks are added to the retrieved pool and everything is reranked together. Each synthetic chunk now marks where its level falls on the reranker's scale. To prune, you pick the lowest level worth keeping and drop every real chunk that ranks below its anchor; the anchors themselves are discarded and never reach the generator. The cost is one LLM call on top of a rerank you already run. But the anchors only decide where to cut; they do not change the scores themselves. In our experiments the reranker often confused partially and indirectly relevant chunks with noise, scoring them below plainly irrelevant ones. To keep them, the anchor would have to sit so low that hardly anything gets pruned. We did not consider it further after some initial experimentation.
Budget-select
Budget-select keeps the top few reranked chunks unconditionally and lets the LLM select at most a fixed number of the remaining candidates: keep the top three and add up to five more, say. That keeps the result predictably small, but the cap is also the flaw. How many chunks an answer needs varies from question to question, and once the budget is spent, every further chunk is dropped no matter how relevant it is.
Simplistic keep/drop-list
The simplest approach just asks the LLM which chunks are relevant. Given the question and the chunks, the model returns a plain list, either the chunks to keep or the chunks to drop, with no scores and no grading. We ran it to check whether anything more elaborate actually pays: if a scheme cannot beat asking directly, it is not worth building.
LLM relevance scoring
This is the approach we adopted. The pruner is an LLM call between the reranker and the generator: it receives the question and the retrieved chunks, grades every chunk against a five-level relevance scale written into its prompt, and returns a score for each. We run this as one listwise call over all the chunks. Chunks scoring at or above a chosen threshold are kept, the rest are dropped. This is the scale we used:
score | level | meaning |
|---|---|---|
5 | ESSENTIAL | The answer cannot be produced without this chunk, whether it answers the question directly or is a definition or prerequisite another chunk depends on. |
4 | CONTRIBUTING | Does not answer on its own, but supplies something a complete answer needs in combination with other chunks: a definition, a prerequisite, a constraint, or one part of a multi-part answer. |
3 | SUPPORTING | On topic and plausibly useful, but the answer is likely complete without it, often because stronger chunks already cover it. |
2 | TANGENTIAL | Same domain or shared terminology, no concrete contribution. |
1 | UNRELATED | No meaningful connection. |
Each level is defined in words, so a 4 means the same thing on every query and a fixed threshold is meaningful. The upper levels give partial and indirect relevance somewhere to land, and because the model sees the question and all the chunks together, it can actually recognize them.
The design has more knobs than we can list here, but these are the main ones we experimented with:
Model and reasoning effort. Which model does the pruning, and how much it is allowed to think. Cost and latency come first here: the pruner is paid for out of the money it saves by sending the generator less context, so it has to be a smaller and cheaper model than the generator itself, which rules out the flagship models by construction. The small, fast models all judged similarly, so we picked the fastest and cheapest; tiers like Gemini's Flash family or OpenAI's mini models are good fits.
Threshold. The cutoff on the five-level scale. This is the main dial: a higher threshold drops more chunks and risks recall, a lower one keeps more and costs more.
keep-top-k. How many of the top reranked chunks to keep regardless of the grade they receive. The reranker is reliable at the very top, so guaranteeing the top few protects the strongest chunks from a grading mistake.
How we measured it
We measured every approach and its variations on a labeled evaluation dataset: a set of real questions for which we know exactly which chunks the answer needs, and which the retriever fully retrieves before pruning. The labels make it high quality, but they also keep it relatively small, since this type of annotation does not scale. We measured recall preserved with it, meaning the share of questions that still have all their needed chunks after pruning. At 100%, no question lost a chunk it needed; at 90%, one in ten did.
Afterwards we verified compression, cost, and latency on production data: we replayed the same variations over a random sample of one month of past conversations, a uniform draw across the month rather than the most recent queries, running over the exact chunks each query actually sent to the generator.
The results
Each point on the chart is one variation of a strategy. Take one variation of the LLM relevance scoring pruner: the model grades all the chunks, the top three reranked chunks are kept regardless of their grade, and of the rest only those graded 4 or higher survive. Change the threshold, or how many chunks pass for free, and you get a different point. Every variation we ran appears as a faint point, plotted by the recall it preserved against the compression it achieved. The solid lines connect each strategy's best variations, the ones no other setting of the same strategy beats on both recall and compression at once, so a line shows the best tradeoff a strategy has to offer.
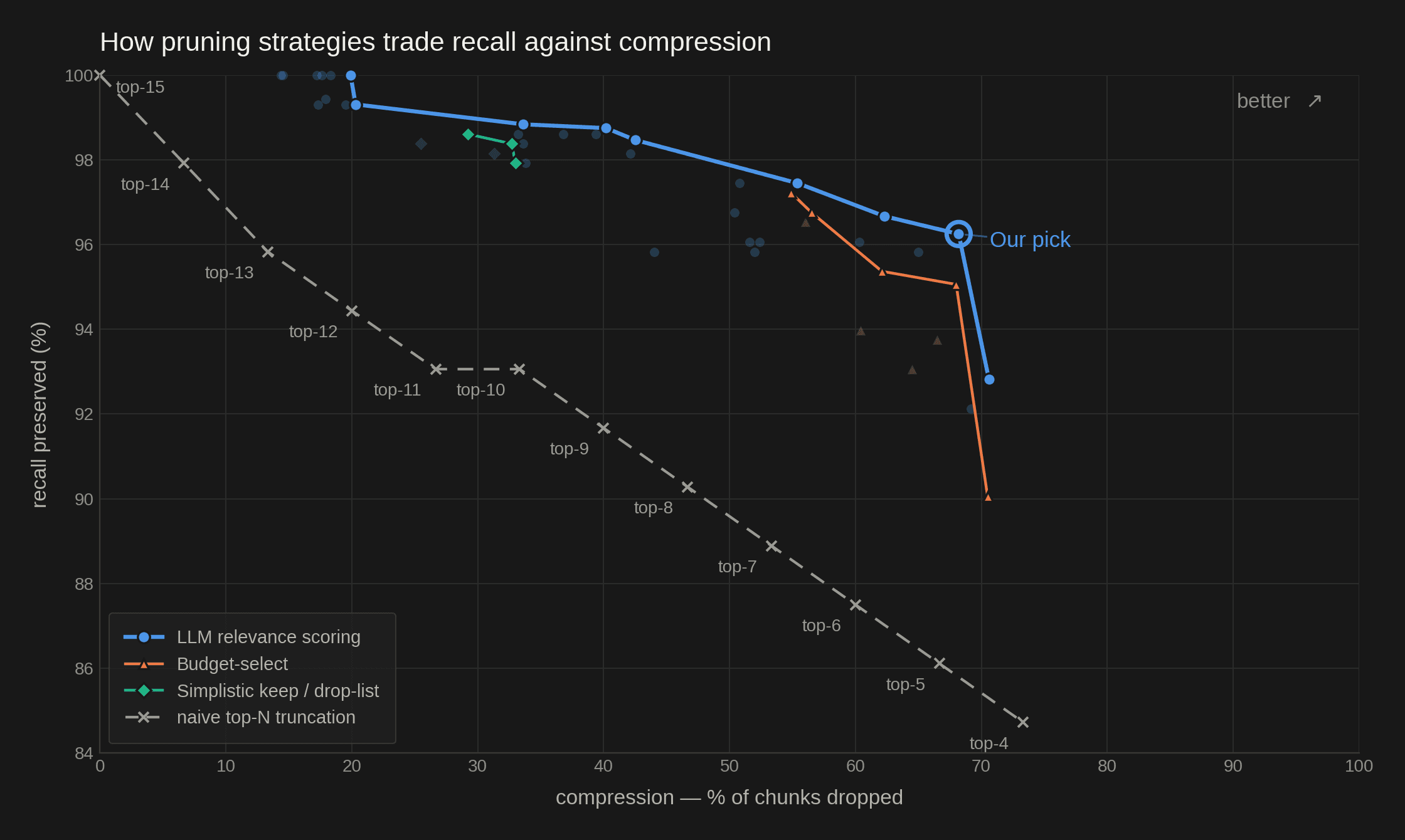
The blue line is LLM relevance scoring, the orange one budget-select, and the green one the bare keep/drop-list. The dashed grey line is the baseline, naive top-N truncation: keep the top N reranked chunks and drop the rest. Reducing the number of chunks returned by the reranker is the easiest possible way to shrink the context, which makes it the natural baseline: any pruner worth running has to beat it.
Every pruner strategy beats that baseline, and by a wide margin. Say you want to hold recall at about 98%. With naive truncation you can drop a single chunk, about 7% compression, before recall falls below that. Every pruner strategy reaches roughly 30% compression or more at the same recall, and the best, LLM relevance scoring, drops close to half the chunks. The blue line in turn strictly outperforms the other two: at any level of compression, LLM relevance scoring preserves more recall than budget-select or the keep/drop-list. So the strategy is settled, and the only question left is where on the blue line to sit: how much recall you are willing to trade for cost.
We picked the point marked on the chart, near the aggressive end. It preserves about 96% recall while dropping about 68% of the retrieved chunks: one question in twenty-five loses a chunk it needed, and in exchange two-thirds of the context is gone. Applied to our end-to-end assistants, where we generate the answer ourselves, that would cut the per-query bill by about 34%, net of what the pruner itself costs to run.
How much latency it adds
The pruner runs between retrieval and generation, in the critical path, so its model call is added to every query, and its speed decides what that costs. Across the production set, the configuration we picked ran in about 0.7 seconds per query. Heavier settings climb fast, so a small model at low reasoning effort is what keeps the addition under a second.
The generation barely speeds up in return: fewer chunks mean fewer input tokens for the generator, so it starts responding a little sooner, but only a fraction of a second, nowhere near enough to cancel out the pruner's own call.
So pruning buys its compression at the cost of a small, fixed amount of latency, well under a second on the configuration we ship. On a latency-sensitive single-shot path that is a real cost to weigh. Inside an agent, which already makes several model calls per turn, one more lean call is marginal.
Where we use it
We released pruning initially where we expect it to be the most interesting proposition: where our retrieval is one tool among many. A lot of our customers build their own agents on top of our retrieval, usually in-product assistants embedded in their application. A typical agent of this kind carries dozens of native tools, listing a user's integrations, querying account data, rendering charts, triggering actions, alongside one knowledge base search tool over the product's documentation. It works through a task in steps, and every tool call pours its output into the same context, so the context grows quickly; limiting how much of it documentation search produces is genuinely valuable. A tighter retrieval result buys room for everything else the agent has to hold and leaves less context to rot. The recall given up is also less dangerous here: an agent that notices something is missing can simply search again.
Our Agent SDK, which you can use to build such an agent end to end, has pruning on by default for its knowledge base search; if you integrate through the retrieval API or our MCP servers instead, it is an option you can enable. Switch it on when a leaner context is worth more to you than the last few points of recall.