The Hard Part of RAG Isn’t Retrieval or Generation
RAG demos are easy. Production RAG is hard. Learn why data pipelines, chunking, evaluation, and operations break real-world systems.

by
Dejan Lukić

Having RAG in your production pipeline (and I should highlight production) is several orders of magnitude harder than running it on pet demo projects. Demos usually come with a document upload feature, a functional LLM chat, and similar, whereas, in production, performance issues quickly surface. The question is: why?

Conceptually, resolving the problem of stale training data seems simple enough. You just need to provide an LLM with context on the fly while chatting with it. Combining a retrieval system with a large language model (LLM) also looks easy: connect the two and expect magic. Internally, that might work. In production, welcome to RAG optimization hell.
The real challenge here is not the retrieval algorithm or the LLM. The difficulty generally lies in the surrounding system design, data ingestion and management, evaluations, and ongoing operations that require substantial human effort.
Are Retrieval and Generation Bottlenecks?
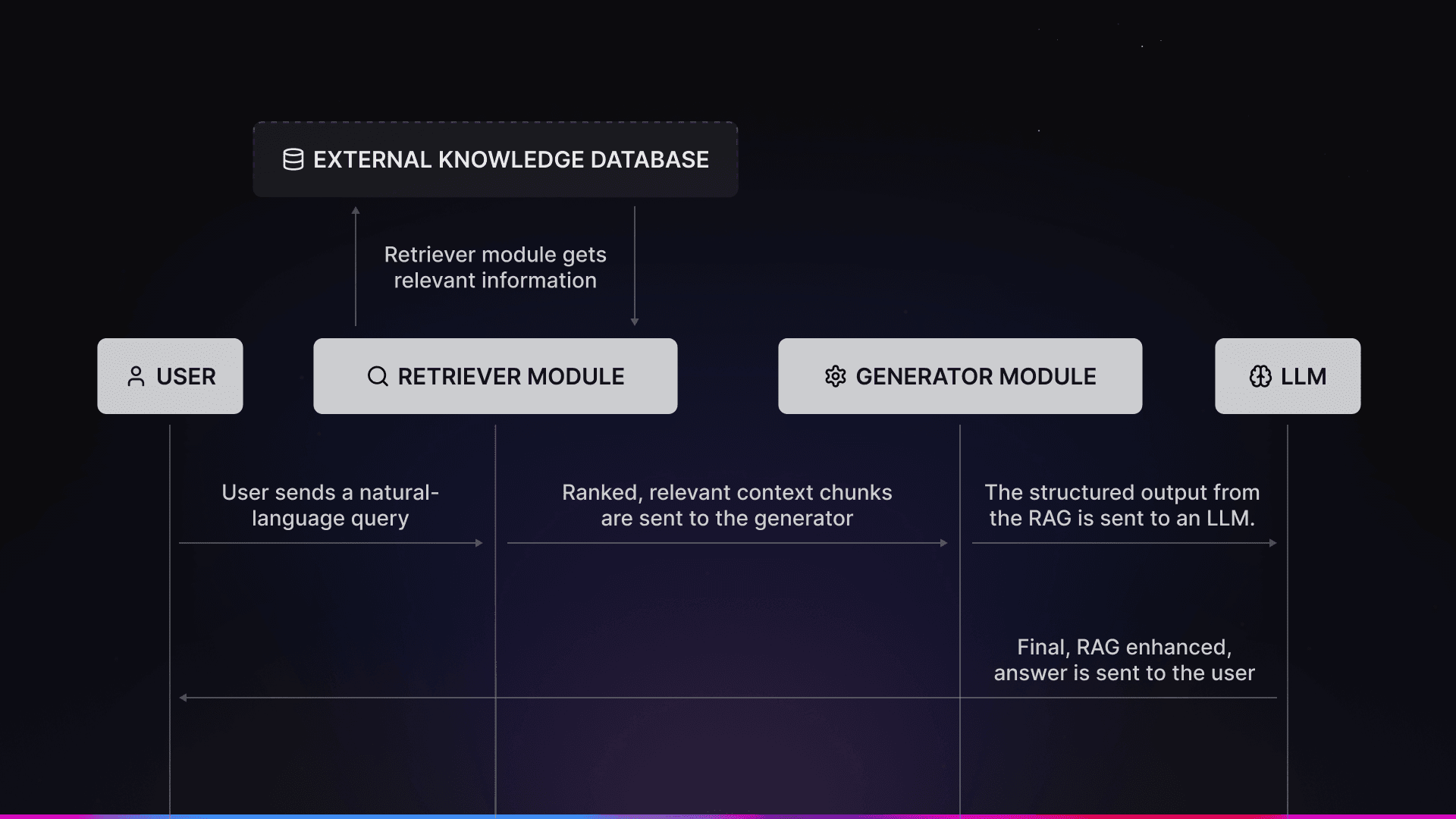
Overview of the AI Workflow
When you get suboptimal results, whether it be hallucinated answers or RAG mistakenly pulling wrong chunks of your data, you might instinctively choose a different retriever or generator mechanism, switch to a different embedding model, move to a larger or newer LLM, or change the chunking method. However, recent research by NVIDIA, Carnegie Mellon University, and BIT Sindri, alongside production experience, suggests these changes usually provide only marginal gains at best.
The failure modes that were identified by their research include situations when correct information exists but is not retrieved, when retrieved content is correct but poorly structured, or when the LLM receives too much, too little, or completely irrelevant content. And when these failures happen, they create a vicious cycle. Poor answers lead teams to blame retrieval or generation, prompting upgrades to embeddings or larger LLMs.
In production, this rarely works for RAG issues. That is because retrieval quality depends less on embedding choices and more on how data is represented and chunked and how context gets constructed and filtered.
RAG studies consistently agree on one point, though: once you get a balance of retrieval and model quality, architectural decisions become an outweighing factor. Embeddings matter, but not as much as you’d think.
What Makes RAG Hard
Okay, setting aside the “who is to blame” debate, the real question is: what actually makes RAG hard to get right in practice?
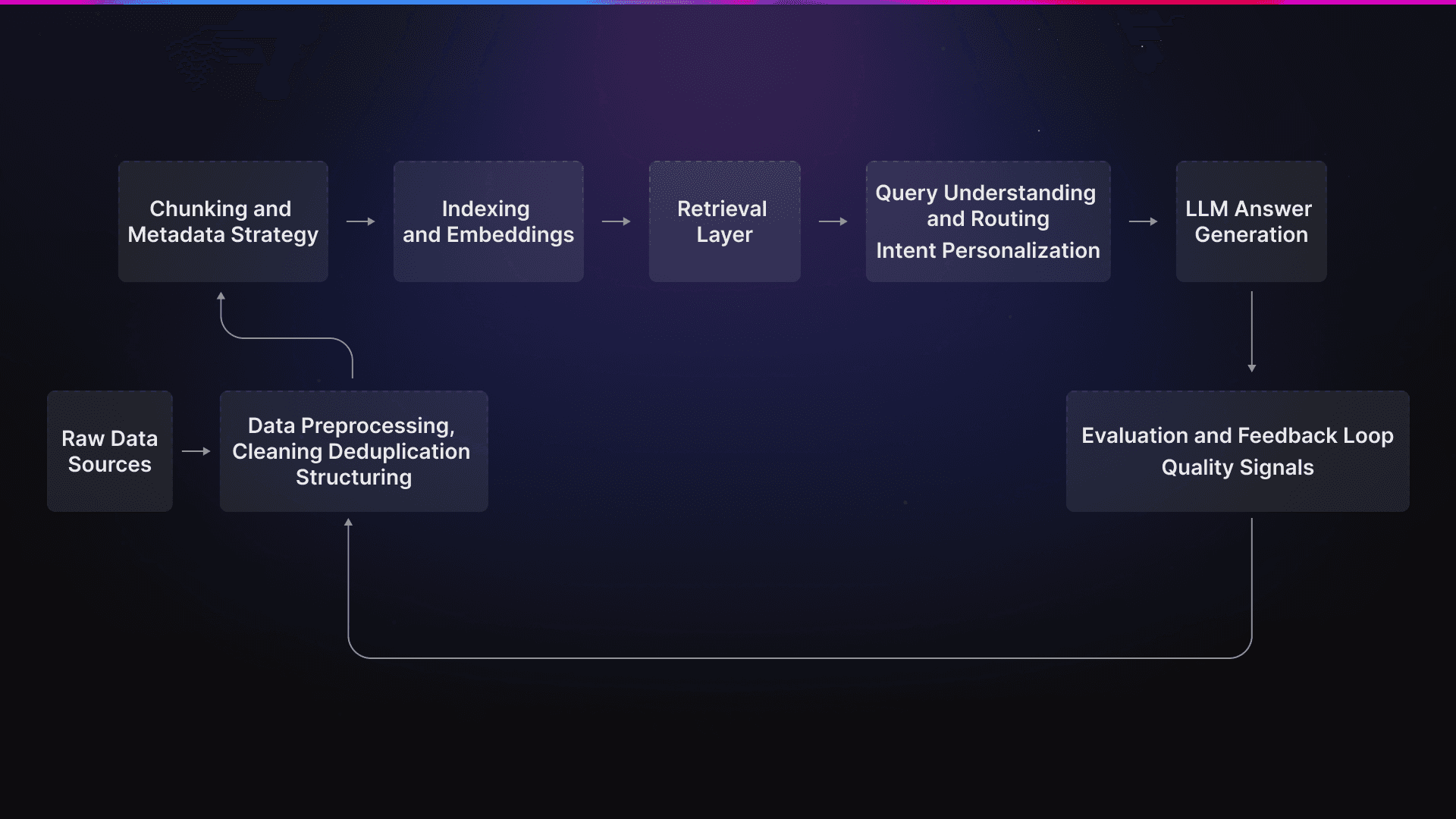
Data processing and LLM-based query answering workflow
Noisy and Incomplete Data
RAG systems inherit all the problems of the data they work on. Documents you upload to RAG are rarely "clean" or complete. Also, they are written for humans to understand. So, how should you tackle this?
Rigorous data cleaning is the way. Retrieval algorithms choose document chunks that could be technically relevant but semantically misleading. A simple example would be apple the fruit vs. Apple the company. To a human, it’s clear they refer to vastly different entities, but in a vector space, there isn’t much difference.
Data Ingestion
Data ingestion isn’t something you do once and then forget. Your RAG will be working with a wide variety of formats and data types: PDFs, docs, external wikis, internal wikis, partner material, ticketing tools, Slack, Discord, GitHub repositories, and possibly more. Each source of data has a specific structure, update cadence, and ways in which it can fail.
On top of that, there are other things you should keep in mind, such as:
Duplicates can drown out better context because they often receive higher relevance scores;
Metadata is good for filtering without having to perform any deeper operations in the pipeline;
Ambiguous "source of truth" decisions lead to contradictory answers;
Broken ingestion pipelines silently degrade retrieval quality over time.
Chunking and Context Construction
Chunking is what fundamentally allows the model to reason. Chunks that are too small lose context, while the ones that are too large overwhelm it and possibly introduce irrelevant information (or lead to hallucinations).
Query Understanding and Routing
User queries are often vague, under-specified, or sometimes just plain wrong. A single query may require different retrieval methods or multiple data sources to answer correctly. For example, you could ask:
Why did our revenue drop?
This is a simple question, but the system might get confused about where to look for an answer. Is it the financial system, the CRM, or somewhere else?
Evaluation and Feedback Loops
Perhaps the most underestimated challenge is knowing whether a RAG system is actually working. In-house benchmarks rarely align with real user behavior and satisfaction. Tools like Kapa.ai have science-backed RAG systems that handle hundreds of thousands of questions weekly, across different user and product categories, data sources, and even languages.
Think about how much data is at disposal here and how useful certain data buckets would be. You can't get that at home.
Scalability
Scaling a RAG engine is difficult. Retrieval mechanisms depend on external vector databases, which often struggle under large data volumes. On top of that, the high entry price, which continues to rise, creates a barrier for real-time application or resource-limited scenarios.
The table below summarizes the key factors that can cause a RAG system to fail:
Why RAG fails | Why it matters |
|---|---|
Messy data | Garbage in, garbage out. If there’s no cleaning process, problems are inevitable down the line. |
Inefficient ingestion pipelines | Systems break down easily if you don’t account for multiple data sources, formats, and their unique failure points. |
Non-optimized chunking | A lack of chunking strategies leads to no context in answers and a higher degree of hallucinations. |
Suboptimal query handling and routing | User prompts are often ambiguous, and the failure to properly route them can lead to poor answers. |
One-dimensional feedback loops | Internal benchmarks are just the tip of the iceberg. If a system has no feedback from real users, you won’t have a clear path for improvement. |
Scalability as an afterthought | Implementation without considering the performance (and costs) with x100 more users leads to rushed decisions and huge financial risks down the road. |
So, how to RAG?
The key to having a RAG that will serve its users lies in a combination of factors.
For starters, high-quality retrieval starts long before embeddings get computed, so investing in data preprocessing is essential. Being deliberate about chunking and query construction is just as important, and so is adding query understanding and routing. After all, not all queries should be handled the same way.
Also, keep in mind that continuous evaluation and feedback loops help the system improve over time, and hybrid retrieval methods that integrate multiple retrievers can further enhance performance.
Still, even though most teams can assemble a RAG prototype quickly, there are some major blind spots when building in-house. One of the most frequently underestimated factors is the ongoing operational cost. Keeping data fresh is a must, as sources constantly change, and maintaining data pipelines demands active engineering time. Of course, this time would be better spent improving the product rather than supporting RAG, which is typically not a core feature.
So, why bother investing several engineers’ time into something that might not be the unique selling point of your product or the feature that brings food to the table? Well, tools like Kapa.ai are built just for that. You do not need to spend thousands of hours DIY-ing a RAG system; you just need to set aside a few hours to configure and deploy a tool that handles everything for you.
Area | DIY RAG | Managed RAG (e.g., Kapa) |
|---|---|---|
Data pipelines | You’re responsible for building and maintaining them. | Handled for you |
Chunking and retrieval tuning | Manual tuning and iteration are required. | Pre-optimized |
Continuous evaluation | You design and run the evaluation process. | Built-in and automated |
Operational overhead | High | Minimal |
Engineering focus | Infrastructure, maintenance, and keeping up with RAG advancements | Product development |
Next Steps
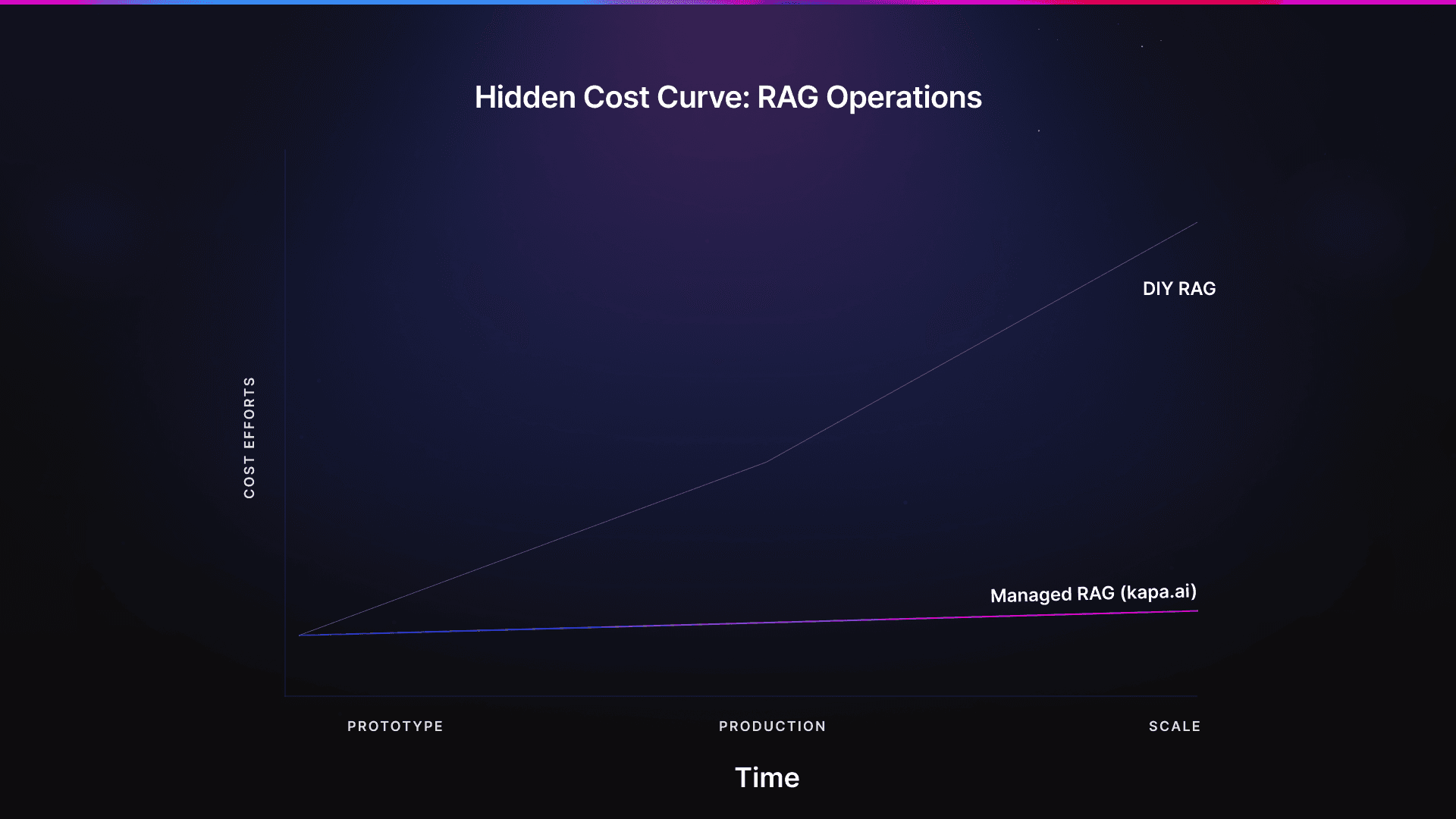
Cost comparison
High five for making it to the end!
As you can see, prototyping a RAG system is cheap. Operating it at scale? Not so much. Think about how much unseen effort, time, and human coordination (which is an overlooked factor in the world of AI) goes into keeping RAG systems reliable every day.
The good news is that when you use Kapa.ai, you don’t need to worry about any of that, except keeping your data sources connected. Book a demo and stop stressing over advancements in AI that you can’t (or don't want to) keep up with.
FAQs
I'm getting poor RAG results. Should I switch to another LLM or a higher-ranked embedding model to fix this?
While it's the most common "first move", upgrading your LLM or embedding model delivers marginal gains at best once you get a balance of retrieval and model quality. You should start by looking at system architecture or the quality of the data ingestion.
Should we build our own RAG system in-house or use a managed service?
This is a million-dollar question, literally. Building a simple in-house RAG system is cost-effective and fast. It gives you so much control and ways to experiment. The true problem arises at scale, which is when it becomes quite expensive. There’s plenty of hidden maintenance costs, like cleaning data, fixing ingestion pipelines, and constant re-tuning.
For companies looking for a solution that works with a large user base, a managed service like Kapa.ai is a better option. You get a plug-and-play RAG without putting a strain on your engineering department.
My RAG system is successfully retrieving the correct documents. So why is the LLM still giving wrong or incomplete answers?
Usually, retrieval precision fails when the data is poorly structured, too noisy, or too fragmented for the model to reason across. We recommend starting from our guide for best data structuring practices for RAG.
How much does it cost to maintain a RAG pipeline in-house?
Industry benchmarks for 2025/2026 by Gartner suggest that a simple enterprise use case, such as document search with RAG, can incur costs of $750k to $1M.
The initial build is only about 10%–20% of the total cost. Ongoing operations make the most of the cost structure. In a production environment, aside from paying for API tokens, you are sacrificing engineering hours to maintain dozens of shifting data sources.