RAG Gone Wrong: The 7 Most Common Mistakes (and How to Avoid Them)
Why do RAG systems fail at scale? Learn the critical mistakes teams make with chunking, data quality, architecture, and evals - plus how to avoid them.

by
Sai Yashwanth

Most teams build their RAG pipelines like a weekend hackathon project instead of treating them as a system engineering problem. Unsurprisingly, the result often feels a bit duct-taped, and the moment you scale your system beyond toy datasets, your pipeline’s weaknesses become glaringly obvious.
There’s also this common misconception that embedded retrieval is “magic.” In reality, the most technical and experienced teams I have worked with actually obsess over fundamentals, such as data cleaning, architectural choices, and evals (which are seriously underrated). All of these core principles matter because retrieval quality degrades rapidly when scaling, and once it goes down, even the smartest LLM can’t magically fix your system.
With the rise of long context window LLMs (1-2 million tokens of context window, which is genuinely wild), some claim RAG is dead and even consider skipping it entirely. In my opinion, long context does help, but it can never replace a good retrieval system. Factor in the cost and latency, and it’s clear why a solid RAG pipeline is so important.
This post is a brain dump of the seven most common mistakes I've seen teams make when building RAG at scale (many of which I’ve made myself). We’ll look into them in detail and explore how avoiding them can help you design better RAG pipelines.
1. Bad Chunking
Chunking is the process of breaking down a document into smaller pieces before converting them into embeddings and storing them in a vectorDB. Sounds simple, right? Most teams default to naive approaches, such as fixed token counts, arbitrary paragraph breaks, splitting every N character, and similar.
But this just doesn’t work.
In my opinion, chunking is one of the most critical steps in a RAG system, and poor strategies can seriously damage retrieval quality. What happens when you cut a sentence, paragraph, or even a logical idea in half? The semantic meaning is lost. And even worse, this loss won’t be isolated. It will propagate across your entire database. The model will see fragments instead of concepts. Contexts will collapse, your embeddings will slowly drift away, and over time, your RAG system will become unreliable.
Incorporating semantics into the splitting process can help us solve this problem. Some of the best practices include semantic chunking, recursive chunking, and overlapping windows. These will ensure that each chunk represents a "coherent unit of meaning." After all, the goal is to create meaningful pieces of information.
2. Poor Data Quality
The “garbage in -> garbage out” saying doesn’t refer to ML models only; it also applies to RAG. Most RAG systems are built on top of the data that’s scraped from somewhere: docs copied from internal wikis, PDF dumps, dirty/uncleaned HTMLs from the internet, and similar. All this ends up being pushed straight into your vectorDB, which then becomes a junkyard where you apply cosine similarity. At first, it might seem to be working with your toy inputs, but in a real-world scenario, it’s bound to fail.
Good RAG systems treat data preparation as a complete step, not an afterthought. That means sanitizing, standardizing, structuring, and filtering the input corpus. Data quality is the foundation of any serious RAG system, and no amount of clever chunking or fancy architecture can compensate for poor data.
3. Picking the Wrong Architecture
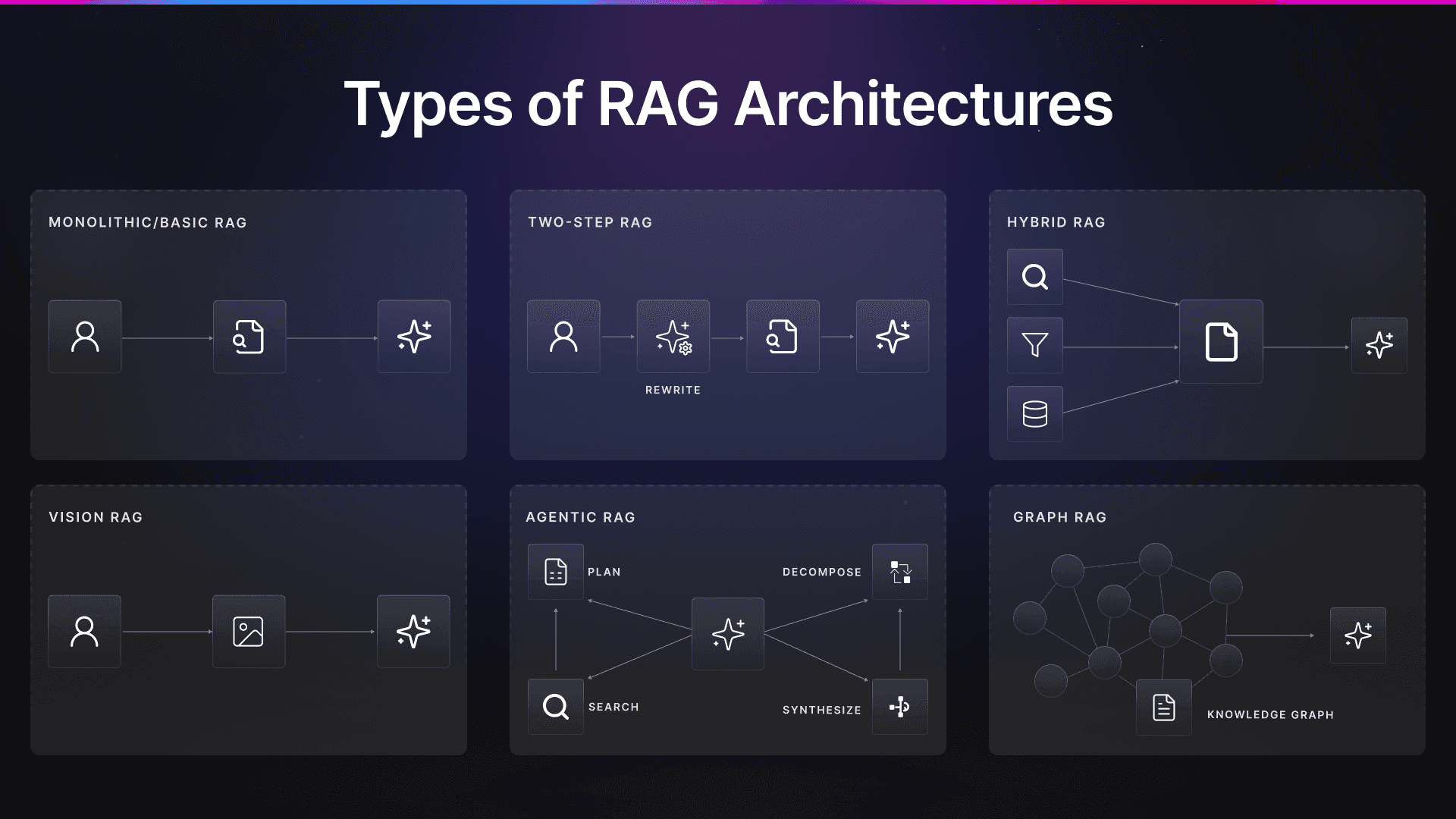
2-Step RAG, Agentic RAG, Hybrid RAG, routing orchestration… These are a few of many buzz words, and the list goes on. The market is full of hype, and teams often copy popular RAG architectures without understanding whether they fit their use case. But remember, architecture should follow requirements, not trends.
For instance, if your queries are simple and repetitive, start with a monolithic RAG (basic RAG) and add two-step query rewriting if the user input is the direct query. Use Hybrid RAG if your data has both structure and text, and consider Agentic RAG when your tasks/use case require reasoning, tools, or workflows. Finally, if there are clear entity groups and relationships, explore Graph RAG, but only after you’ve tried the basics first.
4. No Reranker
Retrieval from a vectorDB is relatively straightforward. Cosine similarity between vectors gets you semantically correct chunks of data, but if you rely on this approach only, you may end up with relevant documents that are not necessarily the best ones. It’s just like picking the nearest neighbor and praying it works. Plus, when you have a huge database, naive RAG pipelines hallucinate and sometimes pull entirely wrong chunks.
A reranker fixes this by taking the top-k retrieved chunks and re-scoring them using a deeper, context-aware model, often a cross-encoder. Instead of looking only at the embeddings, it reads the query and a chunk together and judges how well they match semantically. This boosts the quality of retrieved chunks tremendously and makes the pipeline reliable.
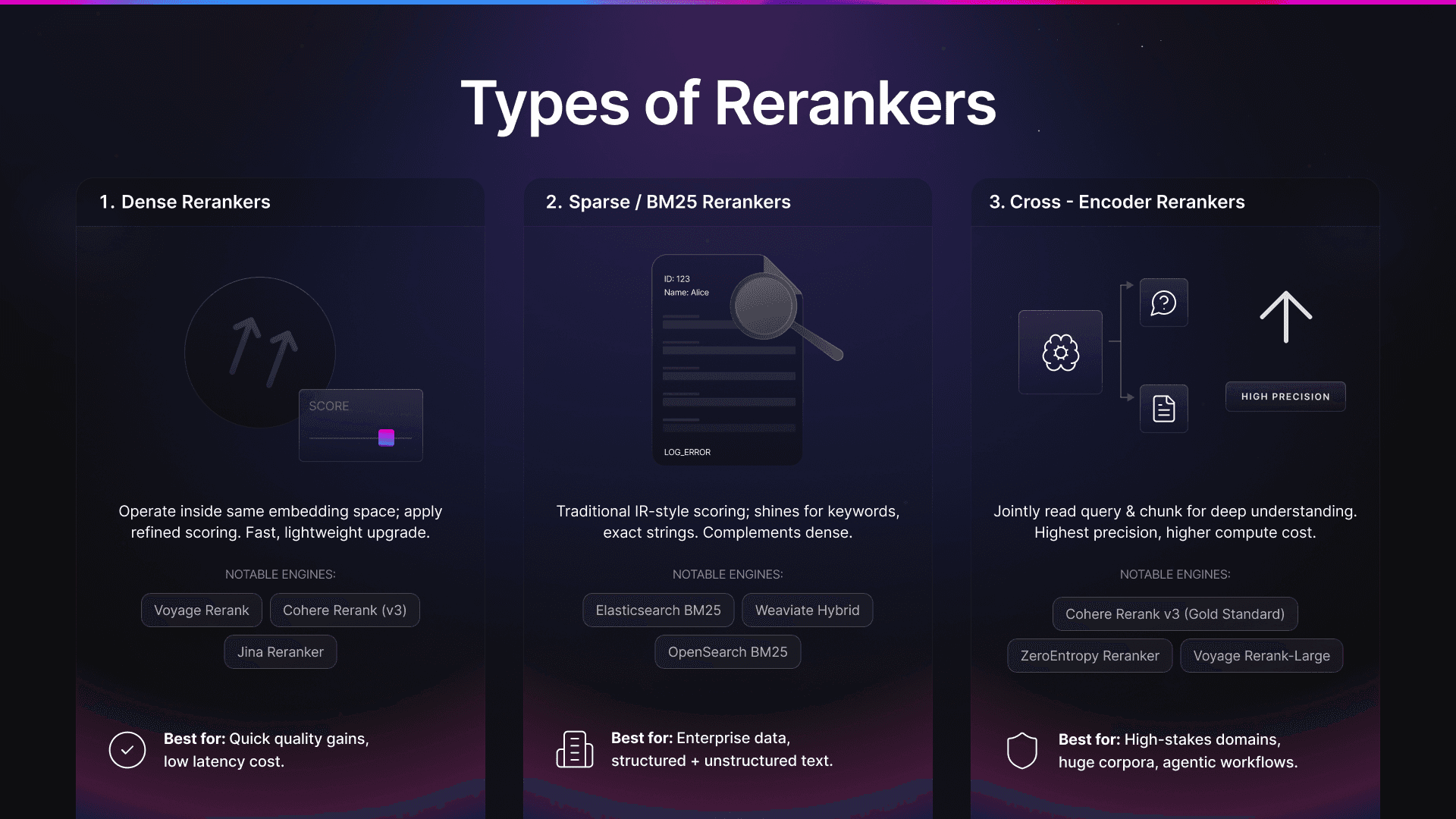
Some common types of rerankers include dense rerankers, sparse/BM25 rerankers, and cross-encoder rerankers. Naturally, they all come with their own set of strengths and weaknesses, so keep that in mind.
5. Embedding Rot
Embedding rot is a silent killer of RAG systems, yet this issue is rarely discussed. It happens when your data, the LLM used for retrieval, or the embedding model become outdated.
VectorDB migrations are painful. As a result, teams avoid re-embedding, which leads to a slow drift toward false information and hallucination. Here’s what it looks like in practice:
Outdated embeddings -> Outdated knowledge -> Outdated output
So, when is it the right time to re-embed your corpus? Well, basically, when the embedding model space improves, when around 10 to 15% of your corpus changes, or when the domain itself changes.
A good practice would be to maintain embedding versioning to track changes. Still, vectorDB migrations are often skipped by teams, and this space clearly needs some sort of innovation.
6. Zero Evals
Skipping evals is one of the most common and dangerous mistakes in RAG systems, yet many teams do this precisely. They choose to rely purely on vibes.
I’m not judging. I’ve been there. And though I’ve shared my views on agent evals in my previous blog post, I have to reiterate: evals matter A LOT. They provide quality control (is the system improving?), regression checks (did a new change break something?) and reliability (does the system behave consistently across different queries?).
Without them, you won’t know when or where your RAG is failing.
A simple evaluation framework can help:
Build a small, high-quality labeled dataset.
Run evals at the retrieval level first. If it fails, generation never stood a chance.
Automate weekly or biweekly eval runs as part of your CI pipeline.
Track metrics over time to monitor trends.
Remember, if you can’t measure it, you can’t control it.
7. Graph RAG Dilemma
Graph RAG has become the latest hype cycle. Many teams see graph diagrams, nodes, edges, and relationships and assume it’s a magic black box that automatically solves retrieval quality.
In reality, Graph RAG is powerful only when the underlying data is not messy and is actually structured. If your raw corpus is bad, then building a graph on top of that mess simply produces messier graphs: noisy nodes and meaningless edges and relationships.
Graphs are powerful tools, but only if built on a solid foundation. You should consider using Graph RAG only when your domain has strong entities and relationships. Keep in mind that latency is a concern for Graph RAG, as well, so using it should come after thorough research regarding your specific use case.
Let’s quickly summarize these issues and how to solve them:
Issues | Core Problem | Why It Fails at Scale | Recommended Fix / Best Practice |
|---|---|---|---|
Bad Chunking | Naive splitting (fixed tokens, paragraphs, chars) | Breaks semantic units, causes meaning loss and embedding drift | Use semantic, recursive, or overlapping chunking so each chunk is a coherent unit of meaning |
Poor Data Quality | Dirty, unstructured, scraped data pushed directly to vectorDB | Garbage data leads to unreliable retrieval regardless of model quality | Treat data prep as a first-class step: sanitize, standardize, structure, and filter |
Wrong Architecture | Copying trendy RAG architectures without matching requirements | Over-complex systems or mismatched designs hurt performance and maintainability | Choose architecture based on use case: Basic RAG → Hybrid → Agentic → Graph (only if needed) |
No Reranker | Reliance on cosine similarity alone | Top-k results may be relevant but not optimal; increases hallucinations at scale | Add rerankers (cross-encoder, dense, or sparse/BM25) to rescore retrieved chunks |
Embedding Rot | Outdated embeddings due to model or data changes | Silent degradation → outdated knowledge → hallucinated outputs | Re-embed when models improve, 10–15% of data changes, or domain shifts; version embeddings |
Zero Evals | No systematic evaluation; relying on intuition | Failures go unnoticed; regressions slip into production | Build labeled eval sets, test retrieval first, automate CI evals, track metrics over time |
Graph RAG Dilemma | Using Graph RAG on messy or unstructured data | Noisy nodes/edges, higher latency, little benefit | Use Graph RAG only when data has strong entities & relationships and latency is acceptable |
What the Future Holds
A RAG system becomes outdated in less than six months if not maintained properly. It’s far from “set and forget”; in fact, it's a continuous process that requires constant improvement, optimizations, refinement, and updates.
As we move toward the agentic era, such a mindset becomes even more important. RAG is not just a feature. When treated like a production system, it becomes one of the most powerful tools in your stack.
This is exactly how Kapa.ai works. We treat retrieval and evaluation as a systems-engineering problem, with a dedicated Answer Engine and evaluation-driven development to keep accuracy high in real-world, technical use cases.
Our platform is used in production by 100+ companies like Mapbox, Monday.com, Prisma, and Redpanda.
“Kapa.ai is much better at answering questions about Prisma than ChatGPT is”
Soren Schmidt, CEO @ Prisma
This is not magic, its engineering, and teams that embrace this motto will go on to build systems that actually work.
FAQs
Why is fixed-size chunking not the right solution for RAG?
Fixed-size chunking usually cuts sentences in half. This would impact the embedding and retrieval of the RAG system. Your RAG would return the keywords, but the context of those keywords would be off, and the answer wouldn't be 100% true
Why is data quality so important for RAG systems?
The performance of your RAG depends on the quality of the data that the system is built on. Corrupted, noisy data will cause garbage results during the retrieval step, and the LLM will hallucinate even if the prompt is amazing.
When should I implement a reranker?
Always. Rerankers are quality filters and they are effective in improving precision without any lag.
What causes embedding rot and how do I fix it?
Embedding rot occurs when the vector store remains static but the underlying data changes. Essentially, your responses will be based on stale data. Consider re-indexing your store when:
10-15% of your corpus changes,
there are improvements in the embeddings models,
or there are major changes in the domain languages.
Is Graph RAG the best architecture?
No. Graph RAG only works if the data you built it on has clear entity relationships. A knowledge graph built on unstructured text results in a messy graph. My recommendation is to start with a basic RAG first.