How to evaluate RAG systems without relying on vibes
A practical methodology for replacing gut-feel vendor comparisons with scores you can actually trust.

by
Finn Bauer

Kapa is a platform that turns your technical knowledge into AI assistants that can answer product questions across your website, Slack, Discord, and API. As a vendor in this space, we get evaluated all the time.
Before partnering with us, nearly every prospective customer evaluates multiple solutions side by side, whether that is comparing vendors against each other or benchmarking against an in-house build. They should. The problem is that these evaluations often do not produce reliable results.
We have seen every approach.
The most common is what you might call a vibe test: people across the company each try the competing solutions with whatever questions come to mind and report back an impression. There is no shared test set, no scoring criteria, and no way to compare results systematically.
A more structured version is to curate a test set and have people score the answers manually. This is better, but human evaluators are inconsistent. Style preferences creep in: one reviewer penalizes an answer for being too verbose, another rewards the same answer for being thorough. Formatting and tone get overweighted relative to potentially more important metrics like factual correctness.
In both cases the outcome is the same: the team has a vague sense that the options were comparable, but nothing concrete enough to support a confident decision.
Evaluating RAG systems well is genuinely difficult, so we wanted to give our take. Our research team works on evaluation continuously, and some of the core approaches we use for our own offline evaluations translate well to anyone comparing solutions. This post distills those into a methodology you can apply whether you are evaluating us, a competitor, or a system you have built in-house.

Recommended Approach
The approach we recommend is to build a test dataset and score it using an LLM-as-a-judge. LLM-as-a-judge is a widely discussed pattern, but the implementation details determine whether it produces meaningful results or scores that are just as unreliable as manual review. The process has three steps:
Source eval data: gather representative questions from real user interactions.
Create test cases: turn those questions into structured marking criteria that an LLM can score against.
Evaluate: run vendor responses through an LLM judge and analyze the results.
Before diving into each step, it is worth defining what to measure. For an application like Kapa, where the agent answers technical product questions, two metrics matter most:
Factuality: Does the system give correct answers? When a user asks a technical question, the response needs to be factually accurate.
Uncertainty: Does the system understand its limitations? When the answer is not in the indexed sources, saying "I don't know" saves the user the time of reading through a confident but unhelpful response.
There are other dimensions worth measuring as well, such as whether the system cites the right sources (citation quality) or whether the answer is actually grounded in the retrieved documents rather than the model's training data (faithfulness). Faithfulness in particular is important but difficult to measure reliably, so we focus on factuality and uncertainty as a practical starting point. If your domain is different, your criteria may be different as well, but the overall methodology remains the same.
Step 1: Sourcing Eval Data
The single most important thing is to use representative test data. If your test questions do not reflect what users will actually ask in production, your results will not predict real-world performance. Coming up with questions based on gut feeling is not sufficient. You need to find a source that approximates real production traffic well.
Where to Find Questions
The right sources depend on your use case. Kapa most often gets deployed publicly on customers' documentation sites, so the suggestions below are tailored to that scenario. If your use case is different, the general principle stays the same: find real questions that closely mirror where the agent will be deployed.
Good sources for Kapa's use case include:
Resolved support tickets where a support engineer gave a verified correct answer. These are ideal because they represent real user confusion and come with a human-validated response.
Forum posts with accepted answers from platforms like Discourse or your community forum. The accepted answer gives you a starting point for what a correct response looks like.
Community messaging channels (e.g., Slack or Discord) where your staff has responded to user questions.
Sampling Guidelines
A few principles will keep your dataset honest:
Sample randomly. Do not cherry-pick questions you think are interesting or representative. Intuition about what users ask can be misleading, especially because a large portion of real traffic tends to come from beginners rather than experts. Random sampling from your actual question sources avoids this bias.
Use recent data. Your product changes over time, and so do the questions people ask about it. Older questions may reference deprecated features or outdated documentation pages.
Include questions with no documented answer. This is critical for testing uncertainty. Deliberately include 10–20% of questions where you know the answer is not covered by the sources the vendor will have access to. A good system should recognize these gaps and say so rather than fabricating an answer.

Manual Review
After sampling, you must review every question by hand. For each one, verify:
The answer is actually correct. Support engineers and forum contributors sometimes get things wrong. If the "ground truth" answer is wrong, your entire evaluation is contaminated.
Cross-check against the source material. For factuality questions, verify that the answer is actually in the sources the vendor has access to. If it only exists in tribal knowledge or an internal wiki, either add the source or remove the question. For uncertainty questions, confirm the answer truly is not documented. Double-check that the information is not buried somewhere in your sources that you might have missed.
Getting a sensible sample size is difficult because each test case requires manual effort. 100 is a reasonable starting point, even though statistically that is still a fairly low number. Of those, roughly 80–85 should have documented answers (for testing factuality) and 15–20 should not (for testing uncertainty).
Step 2: Creating Test Cases
You now have a set of questions with verified answers. The next step is turning them into test cases that an LLM can score, and this is the step most evaluations get wrong.
Why Golden Answers Do Not Work
The natural instinct is to take the correct answer from your support ticket or forum post and use it as a golden truth. The typical approach is then to give both the generated answer and this golden truth to an LLM and ask it to determine whether the generated answer is correct based on the reference. This does not work well in practice.
Real answers are noisy. A support engineer's reply typically contains multiple pieces of information bundled together with tangential context, caveats, and links to other resources. The actual facts that matter are buried in there, and the LLM judge has no way to know which parts are essential and which are incidental. Two perfectly correct answers can look very different on the surface, leading to inconsistent scores.
Write Marking Criteria Instead
Instead of comparing full answers, break each question down into the specific facts that a correct answer must contain. Then define marking criteria that describe what a correct and incorrect answer looks like.
A two-tier system (pass/fail) is the most stable and reduces noise in the judge. If a question involves multiple facts where partial credit is meaningful, a third tier can be added:
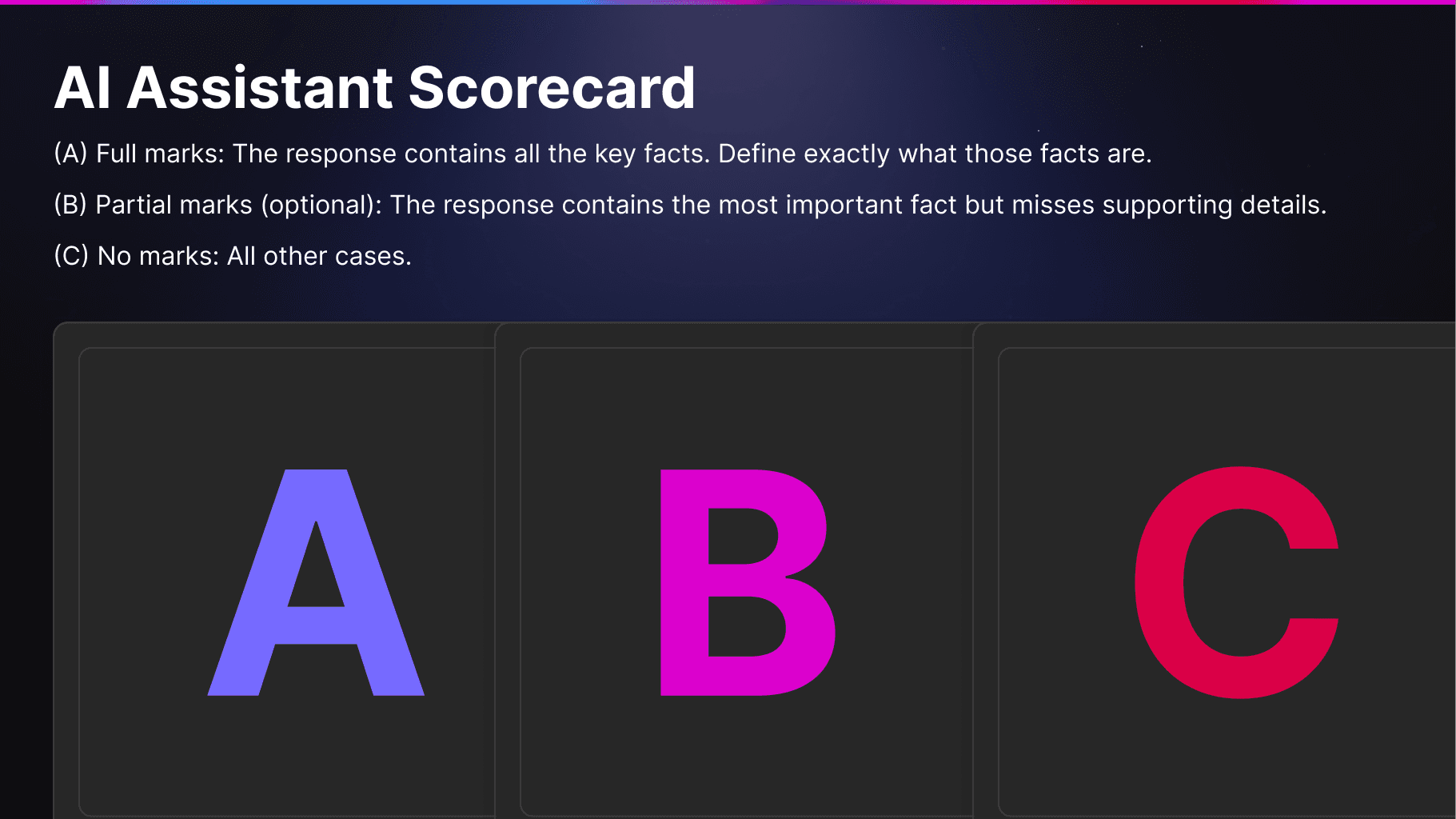
(A) Full marks: The response contains all the key facts. Define exactly what those facts are.
(B) Partial marks (optional): The response contains the most important fact but misses supporting details.
(C) No marks: All other cases.
Examples
Here are some examples from our own eval suite for Kapa's documentation.
Example 1: Factuality
Question: "Can I use Kapa for search?"
Kapa does support search, through both the website widget and a dedicated Search API:
Example 2: Uncertainty
Question: "Can I configure the Kapa widget to only answer in a specific language?"
This is not documented anywhere in Kapa's knowledge base. The correct behavior is for the system to express uncertainty rather than inventing an answer:
Step 3: Evaluating Test Cases
With your test cases and marking criteria in hand, you need to collect responses from each vendor and score them. First, make sure the relevant documents for your test questions are indexed with each vendor. Importantly, freeze your indexed documents for the duration of the evaluation. Because your marking criteria are written against specific facts in specific documents, changing the underlying sources mid-evaluation will invalidate your results. A frozen document set also means you can re-run the evaluation at any time, for example after a vendor ships improvements or after you update your own system.
Then send each question through the vendor's API or interface to generate a response. Once you have all the responses, you can score them programmatically using an LLM-as-a-judge.

LLM-as-a-judge
For each test case, you construct a prompt that gives a judge LLM:
The original question.
The vendor's generated response.
Your marking criteria (A/B/C definitions).
The judge reads the response and selects which marking criterion applies. The prompt looks something like this:
Each grade maps to a numeric score:
Grade | Score | Meaning |
|---|---|---|
A | 1.0 | All key facts present |
B | 0.5 | Core fact present, details missing |
C | 0.0 | Incorrect or missing key facts |
Factuality and uncertainty should be tracked as separate scores since they measure different dimensions. Average the factuality grades across all factuality test cases to produce a single factuality score per vendor. For uncertainty test cases, score each one as pass/fail based on whether the system correctly identified that it could not answer.
A few considerations for the judge model:
Use a strong model. Use one of the largest state-of-the-art models available at the time. The outcome of this evaluation informs an important decision, and this is not the place to optimize for cost.
Enable reasoning. A judge model with chain-of-thought reasoning produces significantly more reliable scores than one that outputs a grade directly.
Run multiple times. LLMs are generally non-deterministic, and ambiguous questions can exacerbate variance. Run the judge multiple times for the same vendor to understand how stable your scores are.
Be aware of self-preference bias. LLMs can prefer responses generated by the same model. If you know which model a vendor uses, try to pick a different one for judging. In practice this can be difficult when evaluating multiple vendors whose underlying models you do not know.
Interpreting Your Results
Your marking criteria will not be perfect on the first pass. Especially during construction, you should review the judge's scores against the actual vendor responses and calibrate. Common issues include:
Marking criteria that are too narrow. A vendor may provide a correct answer via a different path than you anticipated. If your criteria only accept one way of stating the answer, valid responses will be scored as failures. Spot-check C-graded responses to see if the answer was actually wrong or if your criteria missed a legitimate alternative.
Responses that break your assumptions. Vendor responses can be structured very differently from what you expected when writing the criteria. If you find the judge consistently struggling with a test case, revisit the criteria rather than assuming the judge is at fault.
Conclusion
Setting up a proper evaluation takes effort, but it replaces gut feeling with numbers you can actually trust. The key points: use real user questions, not invented ones. Write marking criteria that define the specific facts that matter, rather than comparing against noisy golden answers. Freeze your indexed documents so the ground truth stays stable. Use a strong reasoning model as the judge, and track factuality and uncertainty separately.
Once built, this evaluation set becomes a reusable asset. You can re-run it when a vendor ships improvements, when your documentation changes, or when a new solution enters the picture. The upfront work pays for itself every time you need to make or revisit that decision.