How to Build a RAG Pipeline from Scratch in 2026
Most RAG systems fail in production. Learn how to design, evaluate, and scale a robust RAG pipeline with modern retrieval and monitoring techniques.

by
Bhargob Deka

By 2025, retrieval-augmented generation (RAG) had already evolved well beyond simply chunking a small document, feeding it to your favorite large language model (LLM), and validating the answers yourself. We have now moved into the era of production-grade RAG, where businesses deploy RAG architectures to connect diverse internal data sources and build automated chatbots at scale.
RAG has emerged as a much more practical alternative than fine-tuning an LLM on proprietary data, which is a costly procedure that requires not only significant compute resources but also deep technical expertise and carefully labeled datasets. More importantly, such a system needs to be re-trained every time the data changes.
While the market for RAG is booming, most applications are still struggling to succeed in production. Some of the key challenges include keeping up with constantly changing data, retrieving accurate information across high data volumes and diverse source, and the absence of robust evaluation and monitoring frameworks.
So, what are the solutions?
In this article, we will explore the latest developments that can help you build a robust production-grade RAG pipeline in 2026.
Overview of a RAG Pipeline
At a high level, a RAG pipeline lets you ask questions across your own knowledge base using an LLM. When a user submits a query, the system retrieves related information from your data sources, passes both the query and the retrieved context to the LLM, and the LLM responds with answers that are grounded in external knowledge that it was never trained on.
In order to make it work, the raw data needs to be extracted into a format that the LLM understands first and then broken into smaller pieces so that the LLM can effectively find the right information at the time of retrieval. These chunks are stored as vector embeddings in a vector database, enabling the LLM to quickly find the pieces that are semantically similar to the user’s question at query time.
Now that we understand what a typical RAG workflow looks like, let’s break it down into a few core components that work together end-to-end in an advanced pipeline:
Data ingestion and preparation: Connect to raw data sources, extract information and metadata, and perform data refreshes.
Chunking and indexing: Split extracted texts into smaller chunks and store them as vector embeddings.
Query transformation: Rewrite, augment, or decompose a user query for a better interpretation.
Retrieval and reranking: At query time, identify the relevant chunks from the vector database and rerank them based on relevance scores.
Evaluation and monitoring: Continuously monitor both retrieval and answer quality by using custom or RAG-based metrics on the input-output pairs.
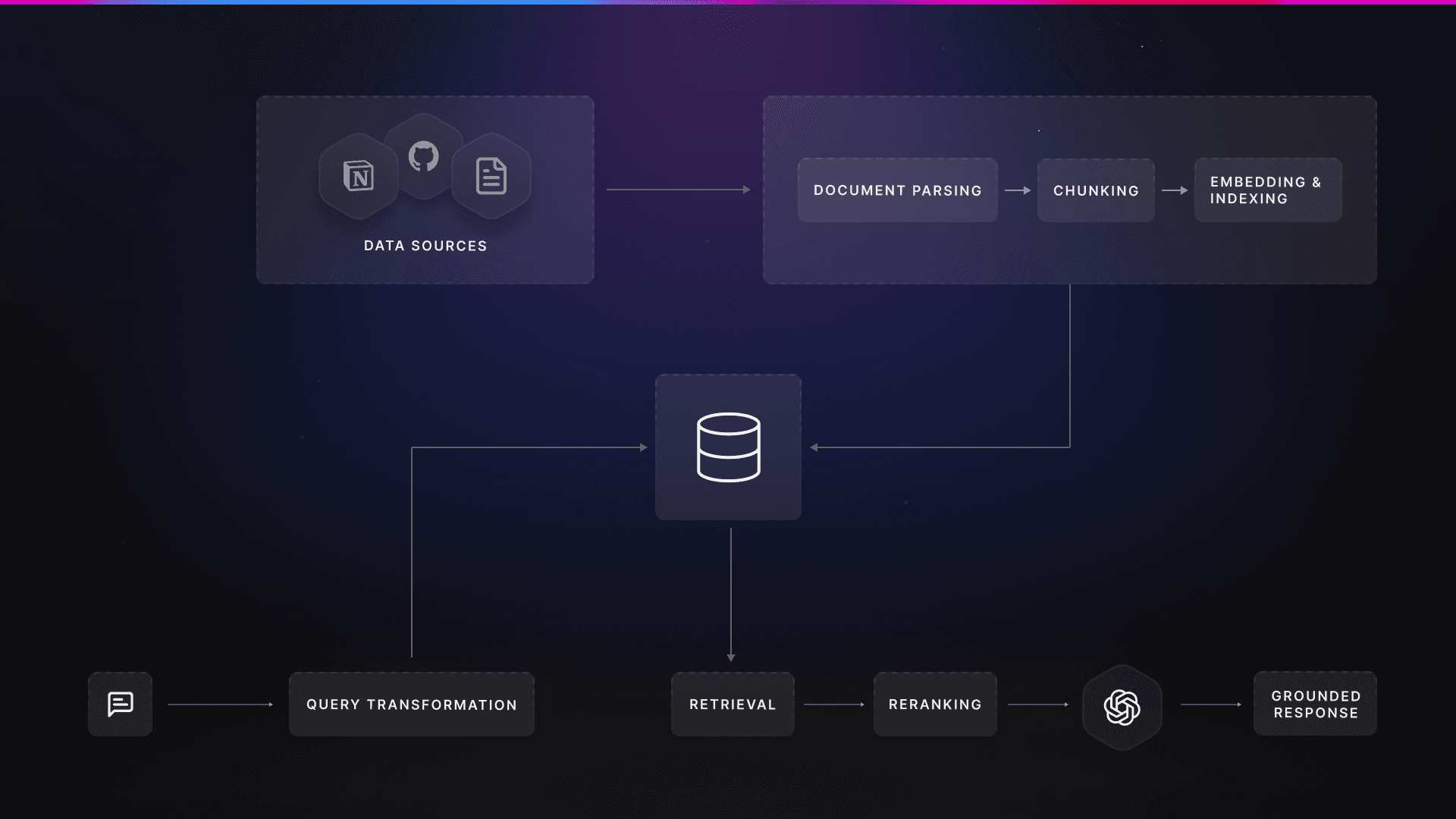
A typical RAG pipeline with its core components
Data Ingestion and Preparation
The first step when building a RAG pipeline is to prepare high-quality, relevant data. AI responses can only be as good as the data they are accessing. The system also needs up-to-date information so that the answers reflect the dynamic changes within the knowledge base.
Let’s say you’ve built a documentation assistant that reads wikis, READMEs, and other user guides. If the information in one of those documents changes and the indexing does not, the assistant will provide outdated answers. Or, the user might ask a question that isn’t covered in the sources. In this case, instead of saying, “I don’t know”, the model is more likely to hallucinate.
These have emerged as core challenges for enterprises where knowledge bases can quickly grow to hundreds or thousands of documents from varied data sources. The key question becomes: how do we ensure the indexed data stays fresh as sources change? The answer lies in implementing a data update strategy.
Data Freshness: Full Re-Indexing vs. Incremental Updates
There are two main strategies for keeping a knowledge base up to date: full re-indexing and incremental update. Depending on your needs, you might choose one approach, or a combination of both.
Full re-indexing would require carrying out all the steps: ingesting data from all sources, formatting them, chunking, and storing the embeddings in a vector store, thereby replacing the old ones with the new. This simple approach ensures all data is kept fresh. However, the process might need significant compute time, and it could potentially cause application downtime. For this reason, it’s normally suggested for a small knowledge base and can be scheduled as a cron job during periods when the app is dormant.
On the other hand, incremental update only focuses on what has changed. This includes old documents that have been updated, new ones that have been added, and documents that have been deleted. In relational databases, change data capture (CDC) is already an established pipeline, with a strict schema that tracks INSERT, UPDATE, and DELETE operations up to a row/column level. However, it is significantly more difficult to apply CDC to unstructured data sources, as there is no schema. Instead, you need to detect file changes either by monitoring timestamps or through commit history in version control systems.
As mentioned, though, enterprises with large knowledge bases often combine both approaches: frequent incremental updates to handle day-to-day changes and occasional full re-indexing.
Another important design decision is determining which data sources to consider and how to prioritize them.
In many domains, a small portion of quality documents can answer the majority of user questions. That’s why it’s useful to categorize the data sources into two groups:
Primary sources: These are normally 10%-20% of documents that would cover 80% of user questions. For example, in a technical documentation assistant, they may include README files, wiki, and doc strings in code.
Secondary sources: This refers to supporting materials that can cover edge cases, such as pull requests descriptions, commit history, etc.
For a minimum viable product (MVP), it’s better to start with a handful of data sources labeled as primary rather than simply increasing the raw count of documents. Over time, other documents can be added to diversify the knowledge base, alongside other secondary documents, which will help improve accuracy for edge cases.
Document Parsing
The next step is to convert the raw data into a format that the LLM can understand. This is handled by document parsers, which convert raw files, such as PDFs and HTML, into clean, structured text. They preserve the original structure by dividing the document using separators like headings, sub-headings, or paragraphs. In addition, they extract tables and images with captions while preserving their layout. Finally, they generate output in LLM-ready formats, such as Markdown or JSON.
Popular frameworks include LlamaParse, Unstructured.io, Docling, and LLMWhisperer. According to a benchmarking test, Unstructured.io seems to have a slight edge compared to others in table extraction while API-based frameworks such as LLMWhisperer provide easy integration.
Once we have extracted the data, the next step would be to trim it down into smaller pieces for faster retrieval. This process is known as chunking.
Chunking and Indexing
Chunking breaks the documents into smaller parts so they can fit into an LLM’s limited context window. Smaller focused chunks allow for faster retrieval and more precise search over the database. An added benefit is the lower computational cost of feeding fewer tokens into the LLM instead of feeding entire documents.
Indexing, in turn, is the process of converting these text chunks into vector representations.
Rule-Based and Structure-Based Chunking
The fastest and most common approach is pre-chunking, where a document is broken down into fixed chunks (for example, 500-1,000 tokens) with some overlap (such as 200 tokens). Pre-chunking is simple and easy to test, but it doesn’t take the document structure into account.
Recursive chunking is another variant that tries to maintain the document’s structure while splitting the text. It does so by dividing the document based on separators. For example, the text can be hierarchically split based on paragraphs and then further into smaller units like sentences if it’s too long.
Another advanced option is document-based chunking, where the splitting strategy is based on the type of document. For example, a Markdown file will be split by headers and subheaders, while an HTML page can be split by tags such as <h1>, <p>, or <div>. This approach preserves the logical structure of the document.
Semantic and LLM-Based Chunking
In recent years, semantic chunking has emerged as a popular technique where splitting is not based on rules or structure. Instead, it’s carried out at points where topics in the text start to change or where similarity scores drop below a defined threshold. For complex, high-value documents where creating chunks with correct boundaries is critical, teams often rely on LLM-based chunking where an LLM with custom instructions is used to segment the document into meaningful units.
Another interesting technique is late chunking. Instead of creating the chunks first, the whole document is tokenized using a long-context embedding model. Now, each token contains some information about its broader context, and the document is split into chunks afterward.
For quick testing, pre-chunking or recursive chunking are the way to go. These can work well as a baseline and can be iteratively refined by changing the chunk size, overlapping, or adjusting the strategy based on query results.
Indexing
Once chunks are created, the next step is to convert them into embeddings and store them in vector databases for fast retrieval at query time. There are several options available, including managed services such as Pinecone and Weaviate, as well as self-hosted solutions, like Qdrant. The choice depends on budget and scaling needs. Fully-managed frameworks take care of automatic scaling and deployment but come at a higher cost, while self-hosted ones provide full control but require more engineering effort.
Apart from vector embeddings, each chunk is stored with metadata, such as document ID, author, or creation date. This enables more precise filtering during retrieval.
Query Transformation
In real-world situations, a user might provide a question where the intent is not clear. In such cases, even superior retrieval techniques cannot compensate for misunderstood user intent. Before retrieval starts, we need to transform such user queries so that the most relevant chunks can be retrieved. Query transformation can involve:
Query rewriting, where the LLM is used to rephrase it by adding domain-specific language while preserving the user intent;
Query augmentation, where the query is too short and more information might be needed to understand the intent;
Query decomposition, where a complex query needs to be broken down into sub-queries. Each sub-query goes through the RAG pipeline, and the results are combined into a final generation step.
In practice, you can start with query rewriting while giving clear instructions to the LLM on how to frame the question. Perform A/B testing to see if the prompt instructions are working in the intended way and if the rewritten query makes sense.
Retrieval
Once the documents have been chunked and indexed into a vector database, the retrieval step finds the chunks that are semantically similar to the user query. In practice, many teams have adopted hybrid retrieval, which combines semantic- and keyword-search methods.
In cases where strong jargon or business terms are used, semantic search alone might not provide the user with relevant chunks. In hybrid retrieval, this situation is handled by combining multiple techniques: using a keyword matching method, such as BM25, that retrieves top chunks based on exact or near-exact match, retrieving top chunks based on semantic similarity to the query, and combining both result sets using a ranking algorithm, such as reciprocal rank fusion, to find the final top-k chunks.
Contextual retrieving is a more recent approach. This technique builds on the idea of hybrid retrieval by adding more descriptive context to each chunk before indexing. These contexts are added to the chunks before the BM25 technique is applied, which results in contextual BM25 indexing, as well.
Overall, when both hybrid and contextual techniques are applied, error rates drop by around 69%. However, the effectiveness strongly depends on the context added to each chunk. For example, 50-100 tokens may not always be sufficient to capture how a chunk fits within the broader context of a document. Plus, there is a possibility of adding more noise in case the context generation is not done well.
In order to ensure the right chunks are retrieved, most RAG architectures include a reranking technique to the pipeline.
Reranking
Reranking is typically a two-step process. First, a slightly higher number of relevant chunks or candidates is retrieved using hybrid or contextual retrieval. Then, a reranking technique is applied in order to get a highly curated top-k set based on the chunks’ relevance to the user query.
Cross-encoders, such as BGE reranker, are the most popular models used for reranking. Unlike bi-encoders, which embed the user query and chunks independently and compare their semantic similarity, cross-encoders jointly encode the user query and each document chunk and then pass them through a transformer model like BERT. This allows for fine-grained attention scores across all tokens that comprise both the query and the chunk. The output is a single relevance score that highlights a more nuanced understanding than what bi-encoders can capture with a cosine similarity score. However, using cross-encoders for reranking can introduce higher latency and costs, as each pair of user query and document chunk has to pass through the transformer architecture.
There are numerous fully managed API-based solutions for applying cross-encoder reranking, such as Cohere’s Rerank 3.5, Voyage AI’s rerank-2.5, and rerank-2.5-lite, which are easy to integrate into your RAG pipeline. A single API call can help you rerank your chunks without the need for any infrastructure management.
Even though there is cost associated with these API calls (around $0.025-0.050 per million tokens), this is still reasonable, given that reranking will be applied to a much smaller set of chunks after the initial retrieval and can provide 20%-30% improvement in top-k chunks.
Evaluation and Monitoring
Improving a RAG pipeline is an iterative process. There’s a lot to be learned from failure cases in production. In addition, you may want to try another retrieval mechanism, a newer version of an LLM, or just test with a data refresh. To do this systematically, a production-grade RAG system needs a robust evaluation framework that can assess quality, detect regression, and guide continuous improvements.
Most evaluations start with a simple “vibe check”, where you test out some domain-specific questions and see if your application is able to answer sensibly. Once a baseline version has been achieved, you need to perform systematic evaluations of both retrieval and generation parts of RAG. Teams often rely on manual validations by subject matter experts, and rightly so, as they know the data inside-and-out and are the most reliable source. However, this process leads to a slower development cycle and can be subjective.
Open-source frameworks, such as Ragas and DeepEval, provide standardized approaches for developers to evaluate RAG pipelines. They allow you to conduct experiments where you can generate test datasets, define custom metrics or use ready-made ones (context relevance, context recall/precision, faithfulness), and monitor them in production. These frameworks use LLM-as-a-judge under the hood to score each example in the dataset.
However, they also have limitations. Users have reported that scores are inconsistent between runs for the same input-output pairs. Off-the-shelf, generic metrics that these frameworks provide may appear convincing, but when you dig deeper, you will often find significant inconsistencies and inaccurate scores. Moreover, these frameworks depend heavily on the quality of the LLM and evaluation prompts. Finally, biased results have been reported when the same LLM that generates answers is also used to judge them.
"The kapa.ai team stands out for their thorough and novel evaluations of LLM-based question-answering systems. By constantly testing all permutations of the latest models and academic techniques, they stay ahead in providing trusted solutions to their customers."
Douwe Kiela, Stanford Professor and author of the original RAG paper
For domain-specific use cases, the gold standard is to create your own evaluation framework. This means defining scoring criteria specific to your application, creating deterministic checks on the answers wherever possible, and building ground truth datasets by manually verifying answers to real user questions. Periodic human evaluation on a subset of outputs should always be part of an evaluation protocol, as it is the ultimate source of truth. Frameworks like Ragas and DeepEval are good starting points and can help you scale. However, for production systems, you will often need to implement evaluation logic that is specific to your own use case.
There are other complex frameworks, such as ARES, which creates its own synthetic training dataset in order to fine-tune a small language model to act as a judge and provide confidence intervals on the scores. Compared to Ragas or DeepEval, it is a more robust but also more complex framework that enables faster evaluation cycles.
Why Building This Yourself Is Hard?
By now, it should be clear that building a production-grade RAG from scratch is anything but simple. It goes far beyond chunking a document and feeding it to an LLM.
CTO at Netlify phrased it nicely:
"Everybody thinks they can do it cheaper, faster, smarter. They get 70% there, and then it never makes its way into production."
Dana Lawson, CTO at Netlify
A modern pipeline includes many moving parts, such as:
Data ingestion and freshness: Connecting to diverse data sources and keeping RAG indexing in sync with data sources;
Parsing, chunking, and indexing: Converting unstructured raw data into clean, structured text, designing effective chunking strategies, and embedding and storing chunks and metadata.
Query transformation: Handling vague queries through rewriting, augmentation, or decomposition.
Retrieval and reranking: Designing retrieval and reranking strategies to derive the most relevant chunks.
Evaluation and monitoring: Choosing an appropriate evaluation framework, building test datasets, and designing custom metrics to make continuous checks and catch regressions in production.
In addition to these core components, production-grade systems also need data security, guardrails for sensitive data, and secure deployment. All these requirements make it challenging for many teams to develop reliable RAG pipelines in production.
Kapa.ai as a Production-Grade RAG Framework
Kapa.ai solves this problem by providing a fully managed, no-code RAG platform that handles all the core components of a production-grade framework.
However, what sets Kapa apart is its accuracy. Over the past three years, the team has been optimizing for accuracy by learning from 200+ production deployments. As a result, they are able to perform A/B testing at scale, track improvements over time, and quickly detect regressions.
The core features include:
40+ pre-built data source connectors (Web Crawl, Zendesk, Confluence, etc.) with automatic scheduled data refreshes;
Custom chunking logic optimized for different data sources (Zendesk tickets vs. Confluence pages), offering a fast, cost-effective alternative to LLM-based chunking;
Out-of-the-box deployment integrations that let you go live in minutes, such as an Ask AI widget embedded directly in your documentation site or support ticket deflection integrated with Zendesk;
Built-in analytics that not only track usage but also help identify documentation gaps by showing which questions lack corresponding answers in the source material.
API, SDK, and MCP support, so that Kapa can be used as a tool in agentic workflows with popular orchestrators like LangChain and LangGraph.
Behind the scenes, Kapa has a dedicated research team that constantly tests new models and approaches. Rather than using generic off-the-shelf metrics, they also prefer to write their own custom evaluation logic for each use case to ensure that the generated responses are highly accurate and free of hallucinations.
Final Thought
Building a reliable pipeline in production is a complex repeated process that involves critical design choices and a lot of engineering work. Regardless of whether you choose to build a RAG pipeline from scratch or decide to use a fully-managed platform like Kapa, the key is to start small and iterate fast.
Let failures in testing guide your next set of improvements.
FAQs
What is a RAG pipeline, and how does it work?
At a high level, a RAG pipeline lets you ask questions across your own knowledge base using an LLM. When a user submits a query, the system retrieves related information from your data sources, passes both the query and the retrieved context to the LLM, and the LLM responds with answers that are grounded in external knowledge that it was never trained on.
Why is RAG a better alternative than fine-tuning an LLM on proprietary data?
RAG has emerged as a much more practical alternative than fine-tuning an LLM on proprietary data, which is a costly procedure that requires not only significant compute resources but also deep technical expertise and carefully labeled datasets. More importantly, such a system needs to be re-trained every time the data changes.
Why do most RAG applications fail in production?
While the market for RAG is booming, most applications are still struggling to succeed in production. Some of the key challenges include keeping up with constantly changing data, retrieving accurate information across high data volumes and diverse source, and the absence of robust evaluation and monitoring frameworks.
How do you keep RAG data fresh as sources change?
There are two main strategies for keeping a knowledge base up to date: full re-indexing and incremental update. As mentioned, enterprises with large knowledge bases often combine both approaches: frequent incremental updates to handle day-to-day changes and occasional full re-indexing.
Why is building a production-grade RAG pipeline from scratch hard?
A modern pipeline includes many moving parts, such as data ingestion and freshness, parsing, chunking, and indexing, query transformation, retrieval and reranking, and evaluation and monitoring. In addition to these core components, production-grade systems also need data security, guardrails for sensitive data, and secure deployment. All these requirements make it challenging for many teams to develop reliable RAG pipelines in production. Kapa.ai solves this problem by providing a fully managed, no-code RAG platform that handles all the core components of a production-grade framework.